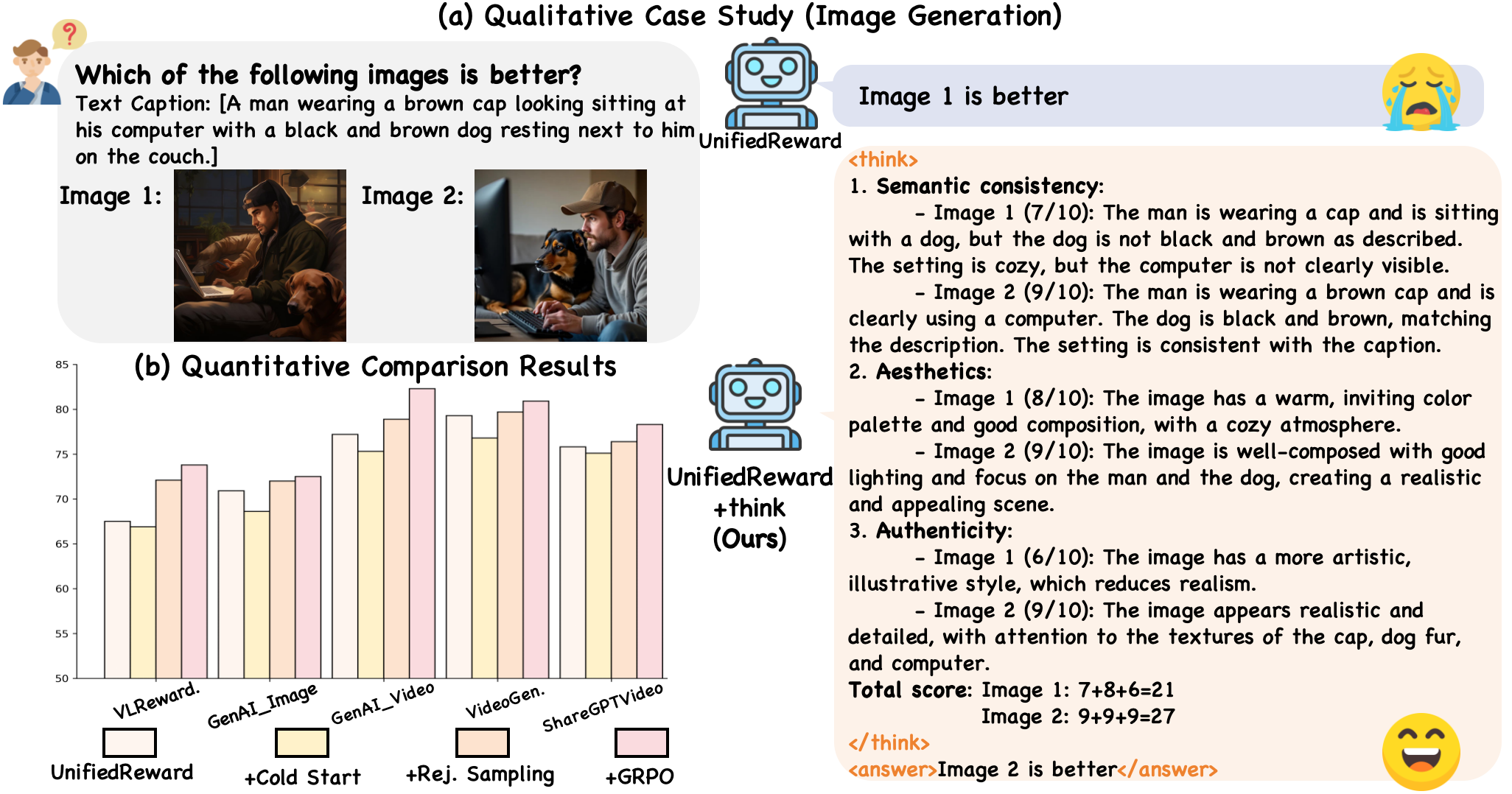
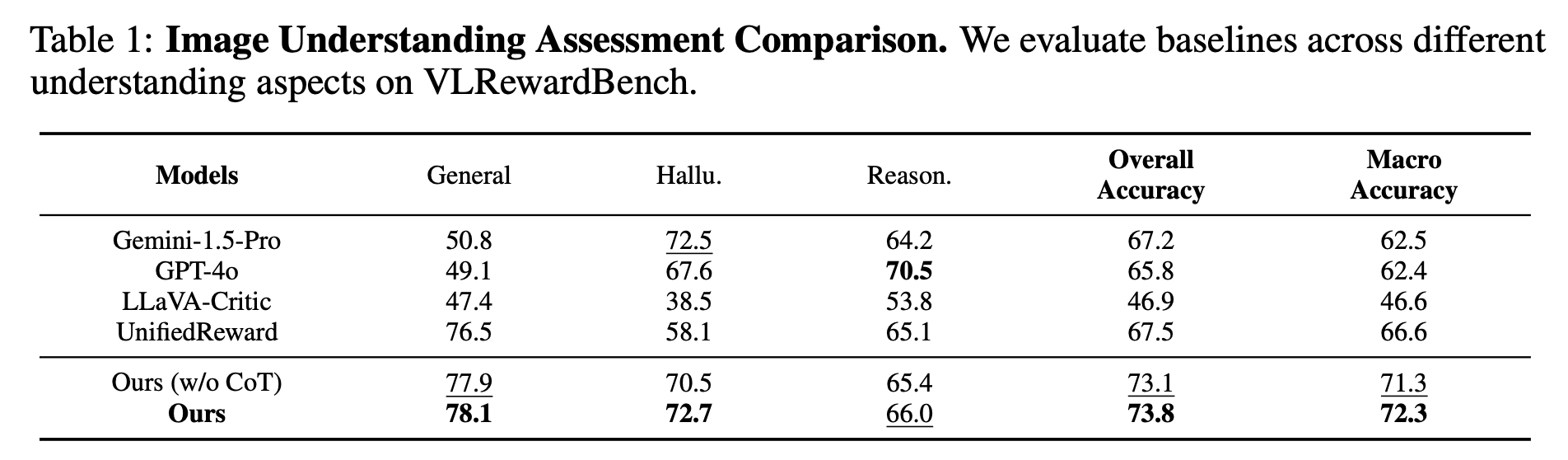
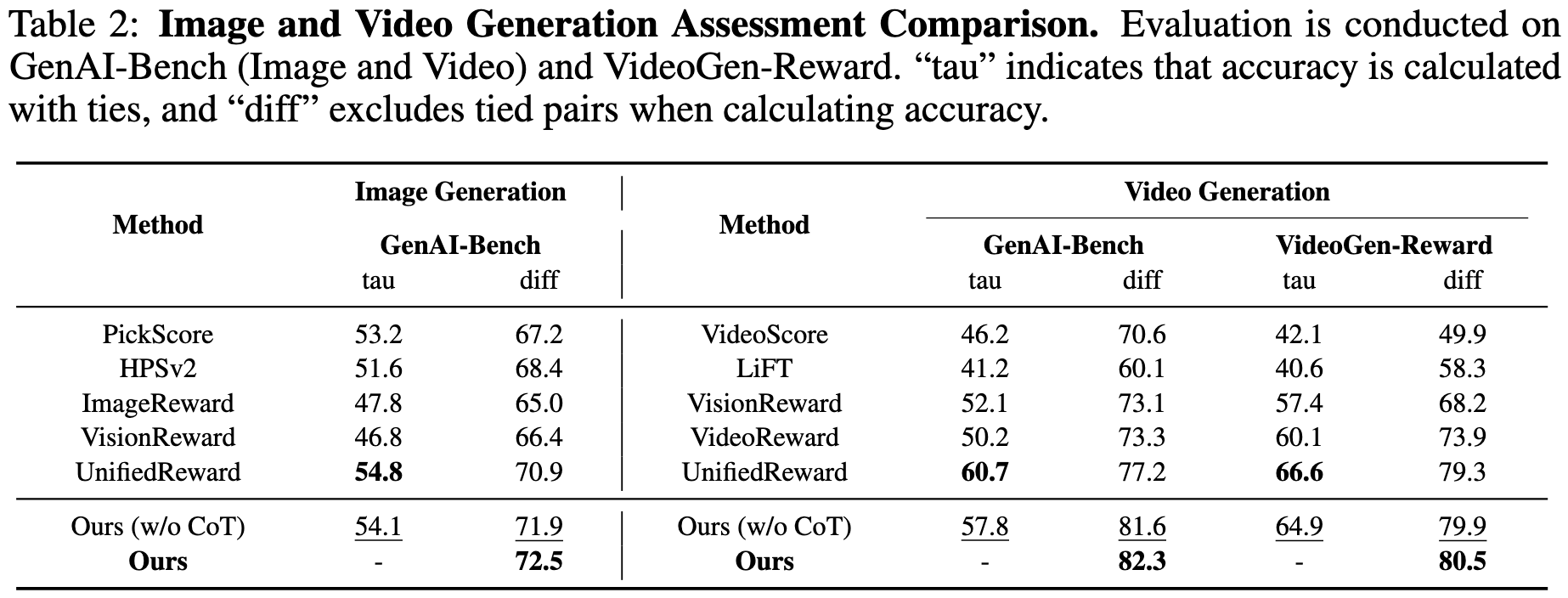
Recent advances in multimodal Reward Models (RMs) have shown significant promise in delivering reward signals to align vision models with human preferences. However, current RMs are generally restricted to providing direct responses or engaging in shallow reasoning processes with limited depth, often leading to inaccurate reward signals. We posit that incorporating explicit long chains of thought (CoT) into the reward reasoning process can significantly strengthen their reliability and robustness. Furthermore, we believe that once RMs internalize CoT reasoning, their direct response accuracy can also be improved through implicit reasoning capabilities. To this end, this paper proposes UnifiedReward-Think, the first unified multimodal CoT-based reward model, capable of multi-dimensional, step-by-step long-chain reasoning for both visual understanding and generation reward tasks. Specifically, we adopt an exploration-driven reinforcement fine-tuning approach to elicit and incentivize the model's latent complex reasoning ability: (1) We first use a small amount of image generation preference data to distill the reasoning process of GPT-4o, which is then used for the model's cold start to learn the format and structure of CoT reasoning. (2) Subsequently, by leveraging the model's prior knowledge and generalization capabilities, we prepare large-scale unified multimodal preference data to elicit the model's reasoning process across various vision tasks. During this phase, correct reasoning outputs are retained for rejection sampling to refine the model (3) while incorrect predicted samples are finally used for Group Relative Policy Optimization (GRPO) based reinforcement fine-tuning, enabling the model to explore diverse reasoning paths and optimize for correct and robust solutions. Extensive experiments confirm that incorporating long CoT reasoning significantly enhances the accuracy of reward signals. Notably, after mastering CoT reasoning, the model exhibits implicit reasoning capabilities, allowing it to surpass existing baselines even without explicit reasoning traces.
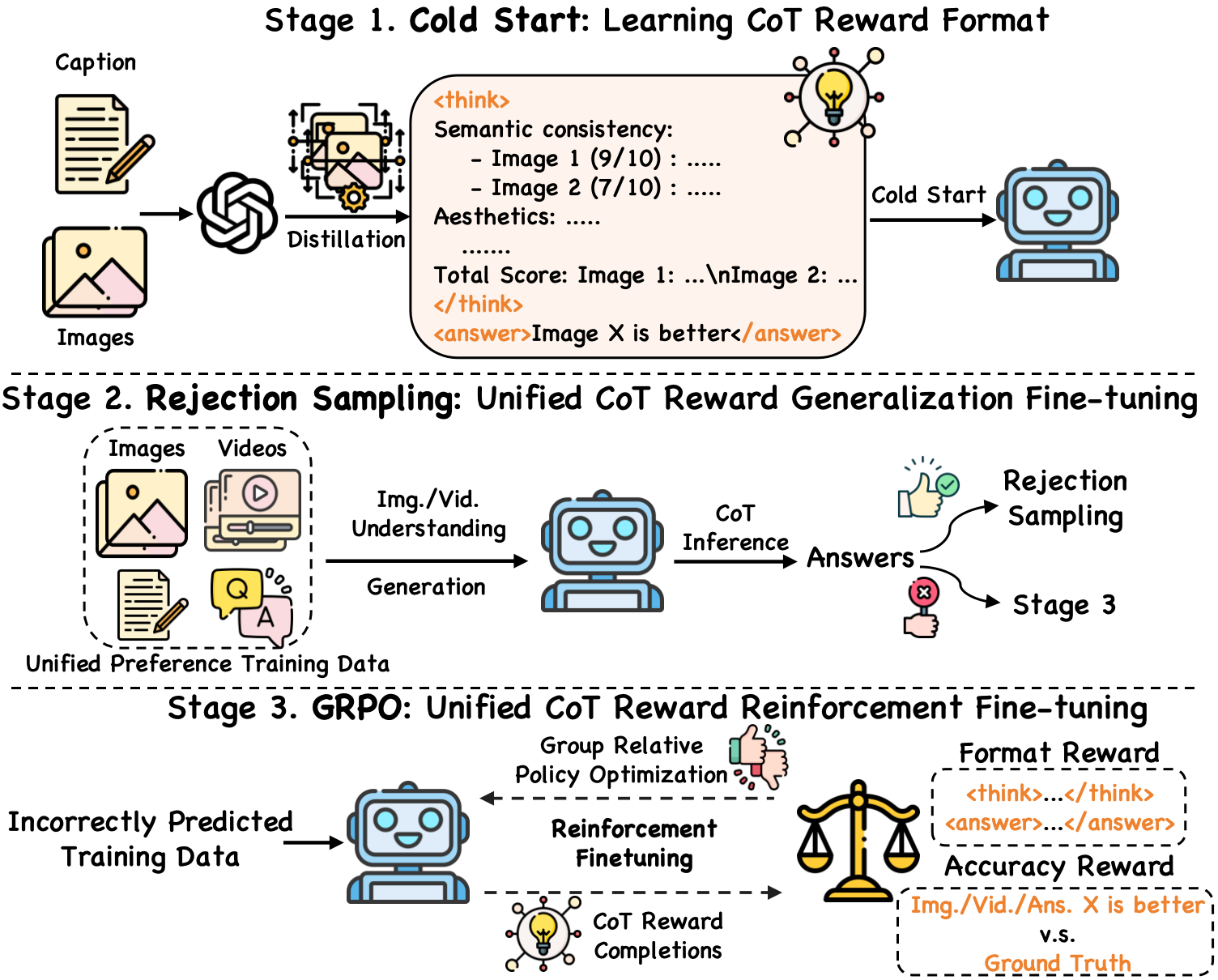
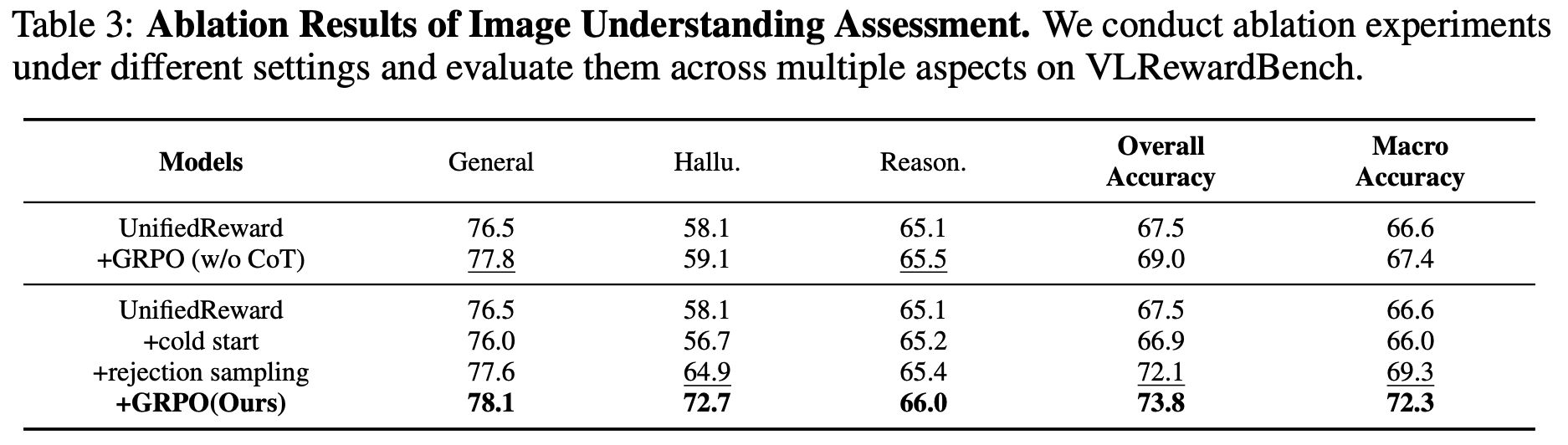
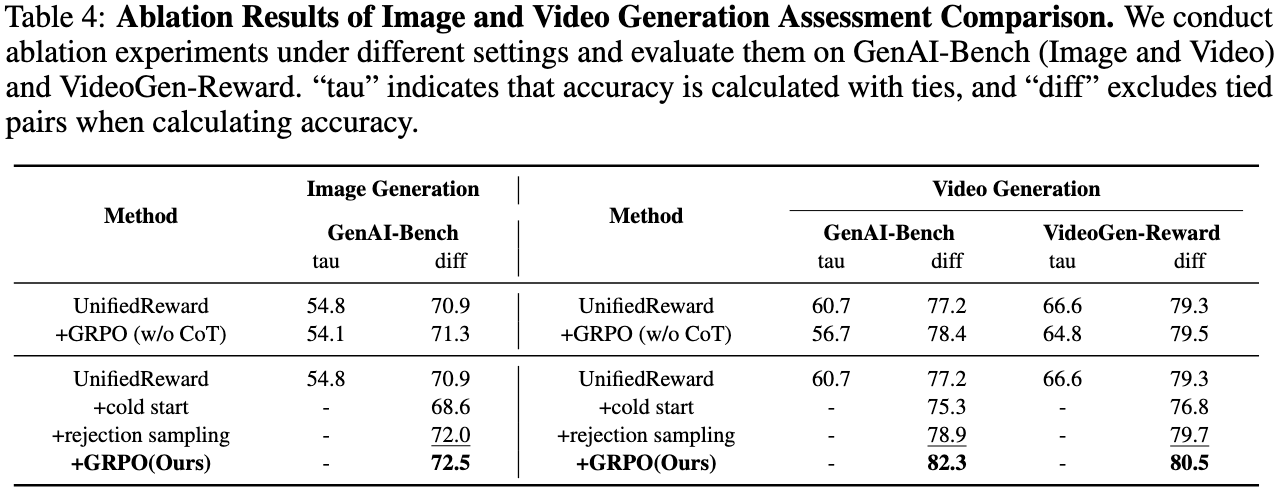
The training pipeline consists of three key stages:
(1) Cold Start: We first distill GPT-4o's reasoning process on a small amount of image generation preference data to initialize the model's CoT reasoning format;
(2) Rejection Sampling: Then, we leverage the model's generalization capabilities on large-scale unified multimodal preference data to elicit its CoT reasoning process across various vision tasks, using correctly predicted samples for rejection sampling to refine the model;
(3) GRPO: Finally, incorrectly predicted samples are utilized for GRPO-based reinforcement fine-tuning to further enhance the model's step-by-step reasoning capabilities.






@article{unifiedreward-think,
title={Unified multimodal chain-of-thought reward model through reinforcement fine-tuning},
author={Wang, Yibin and Li, Zhimin and Zang, Yuhang and Wang, Chunyu and Lu, Qinglin and Jin, Cheng and Wang, Jiaqi},
journal={arXiv preprint arXiv:2505.03318},
year={2025}
}