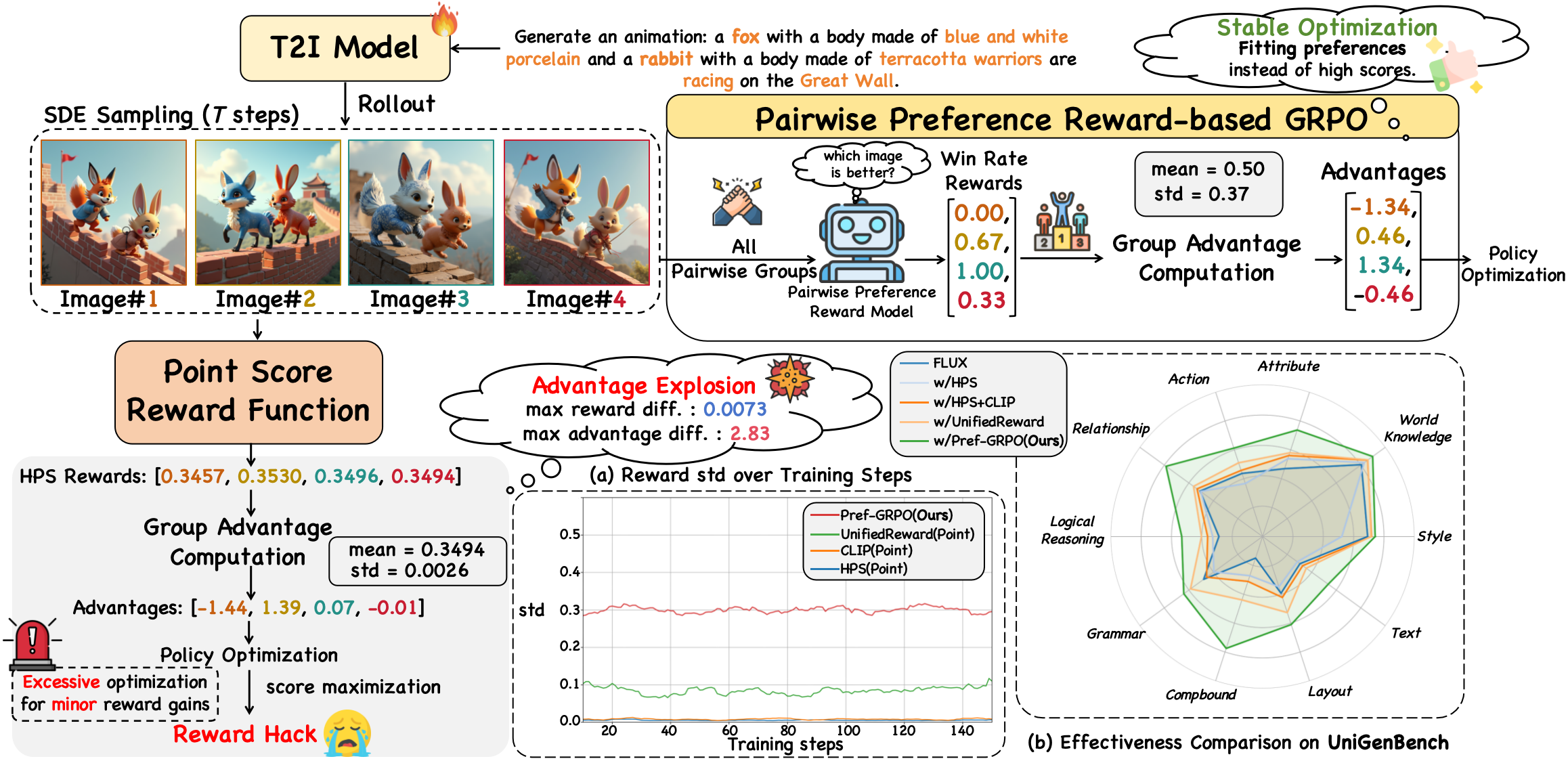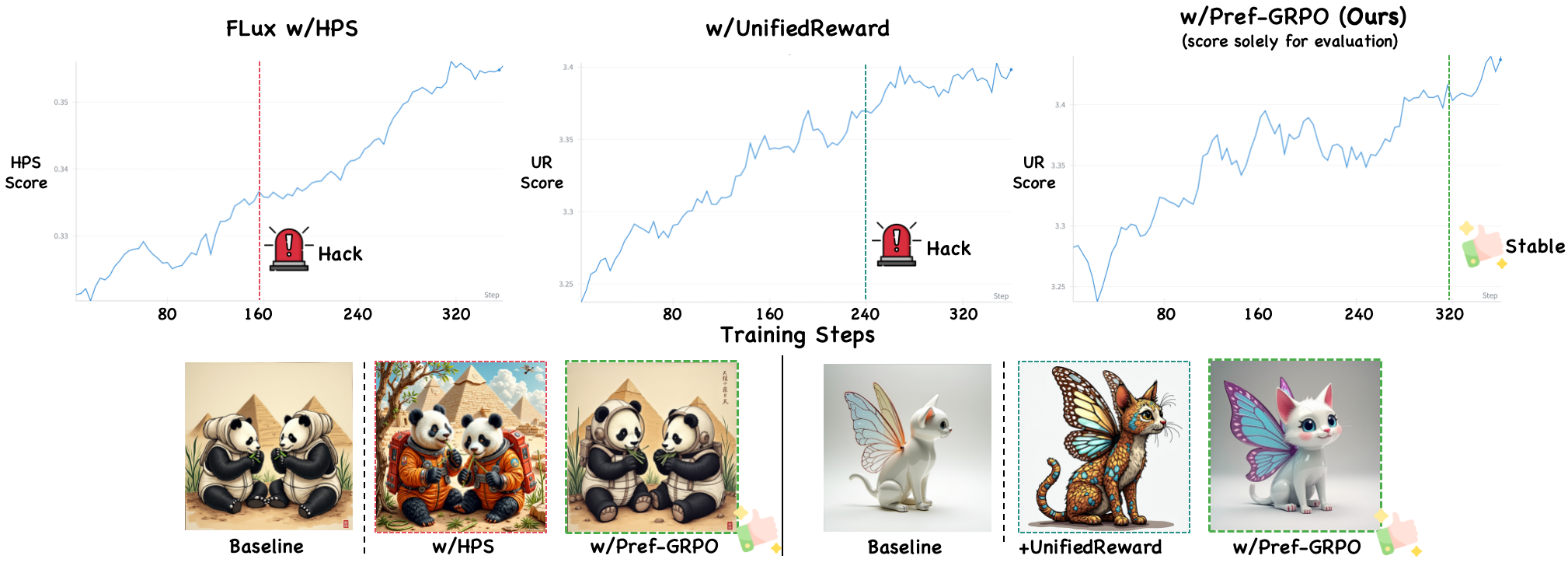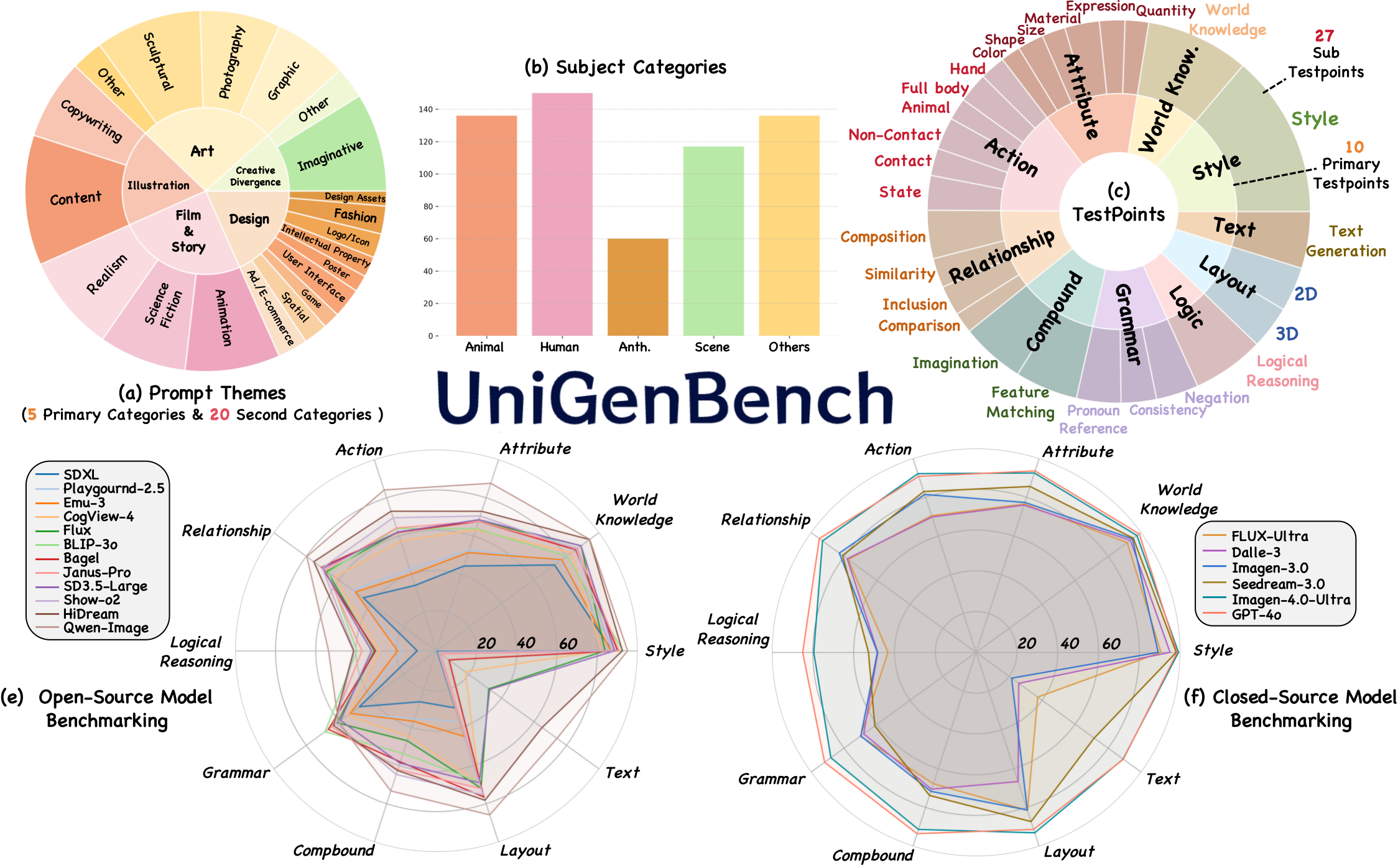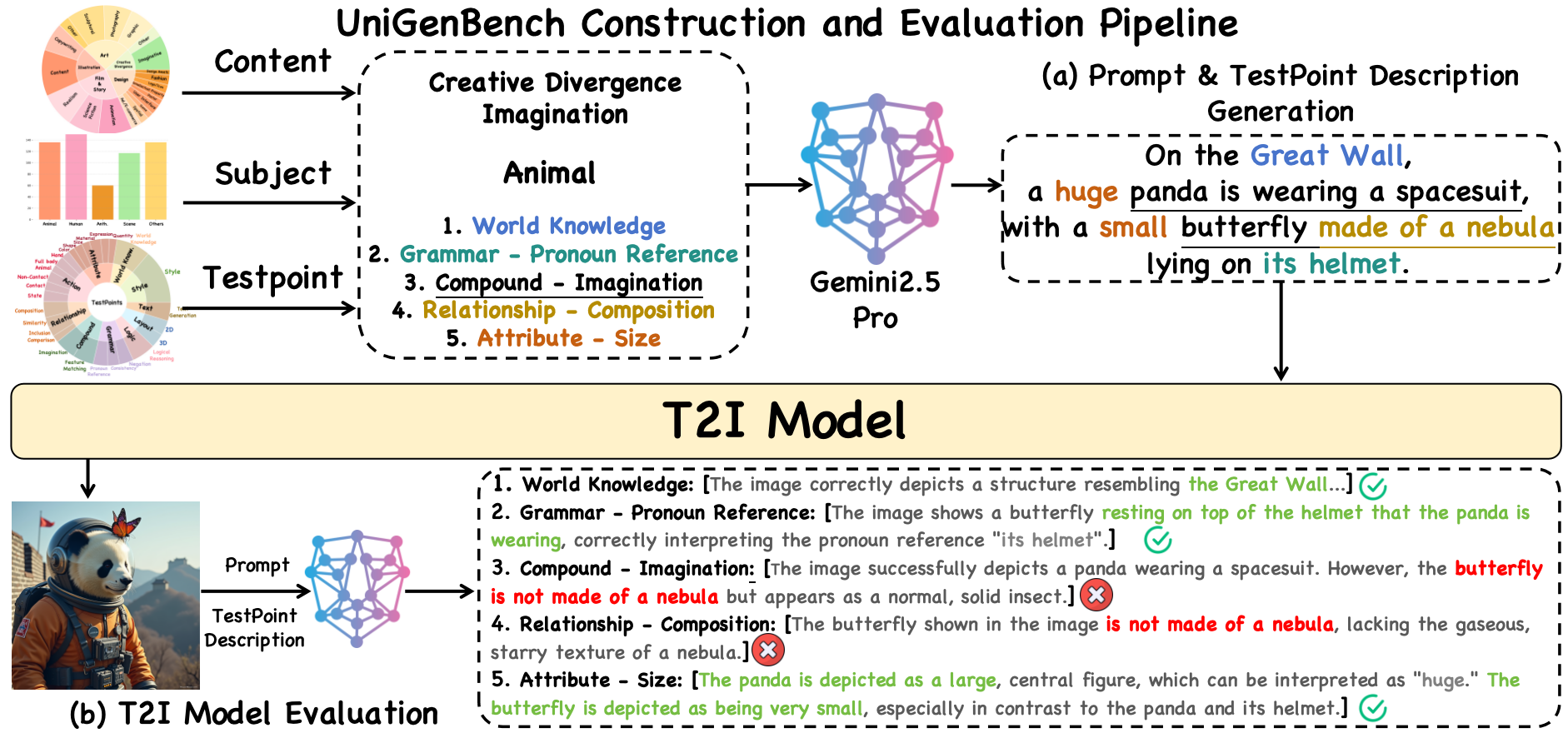
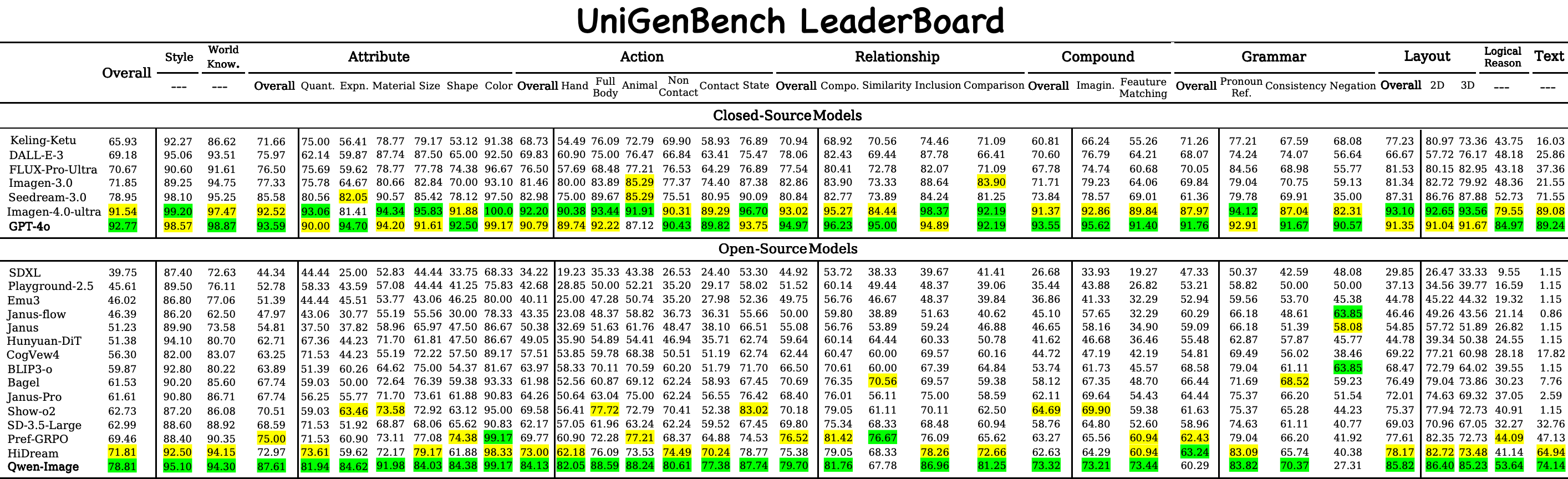
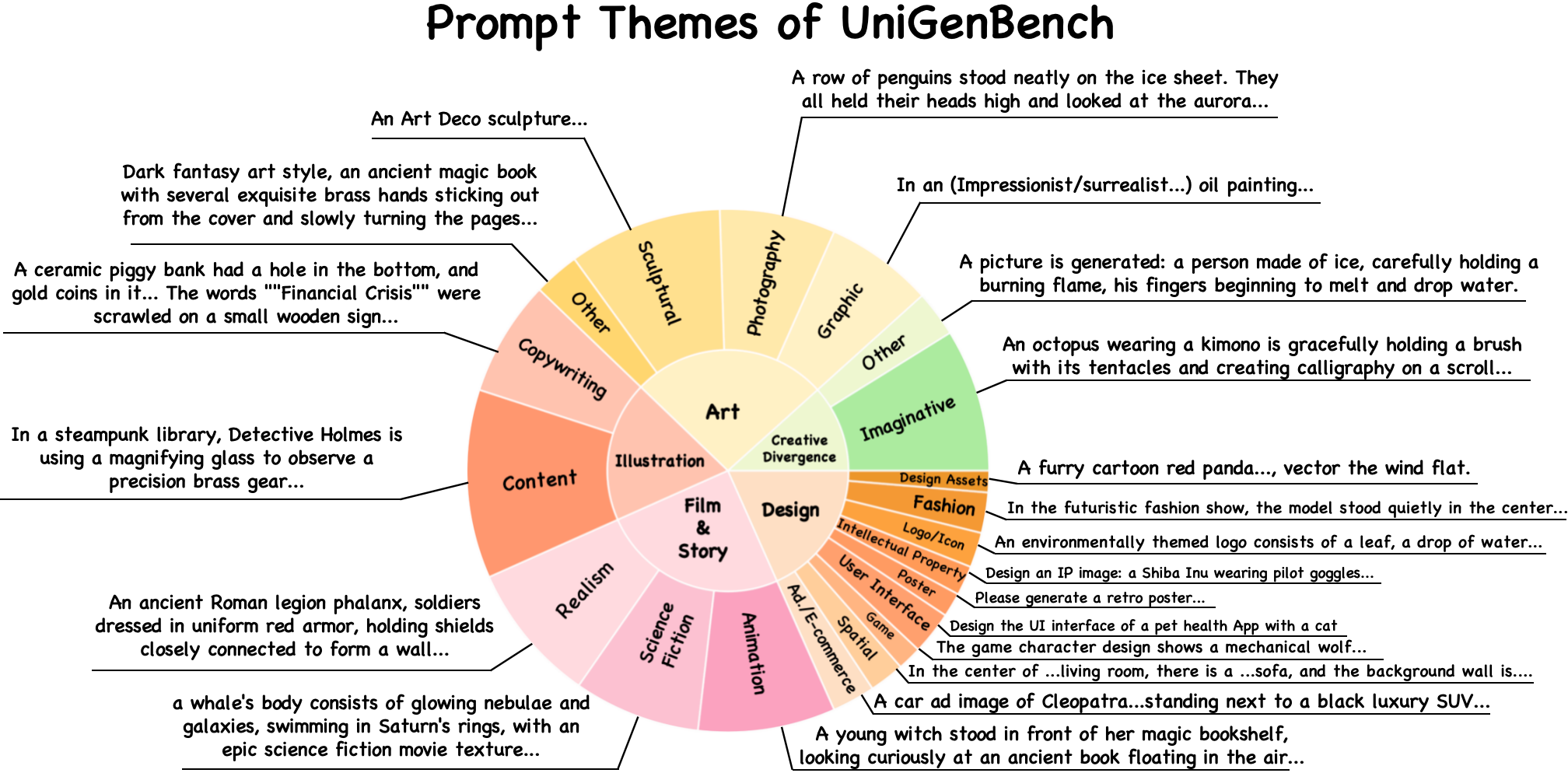
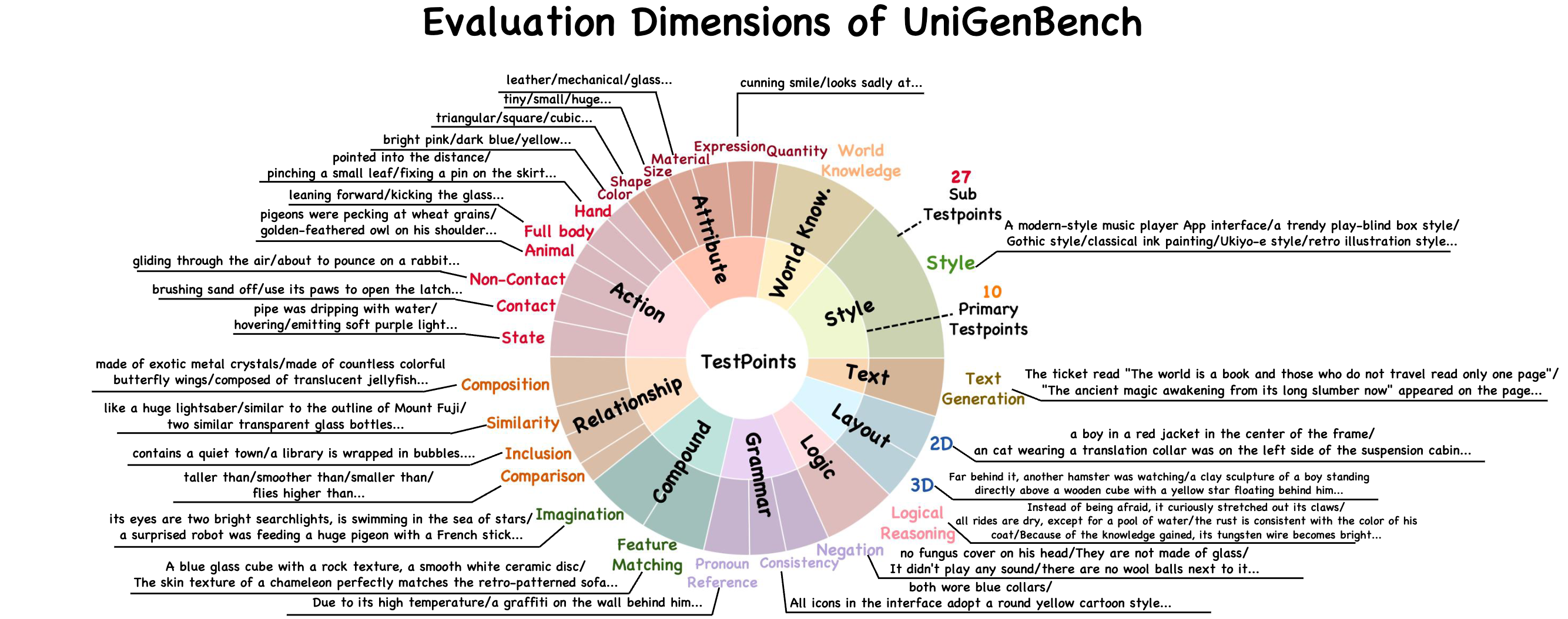
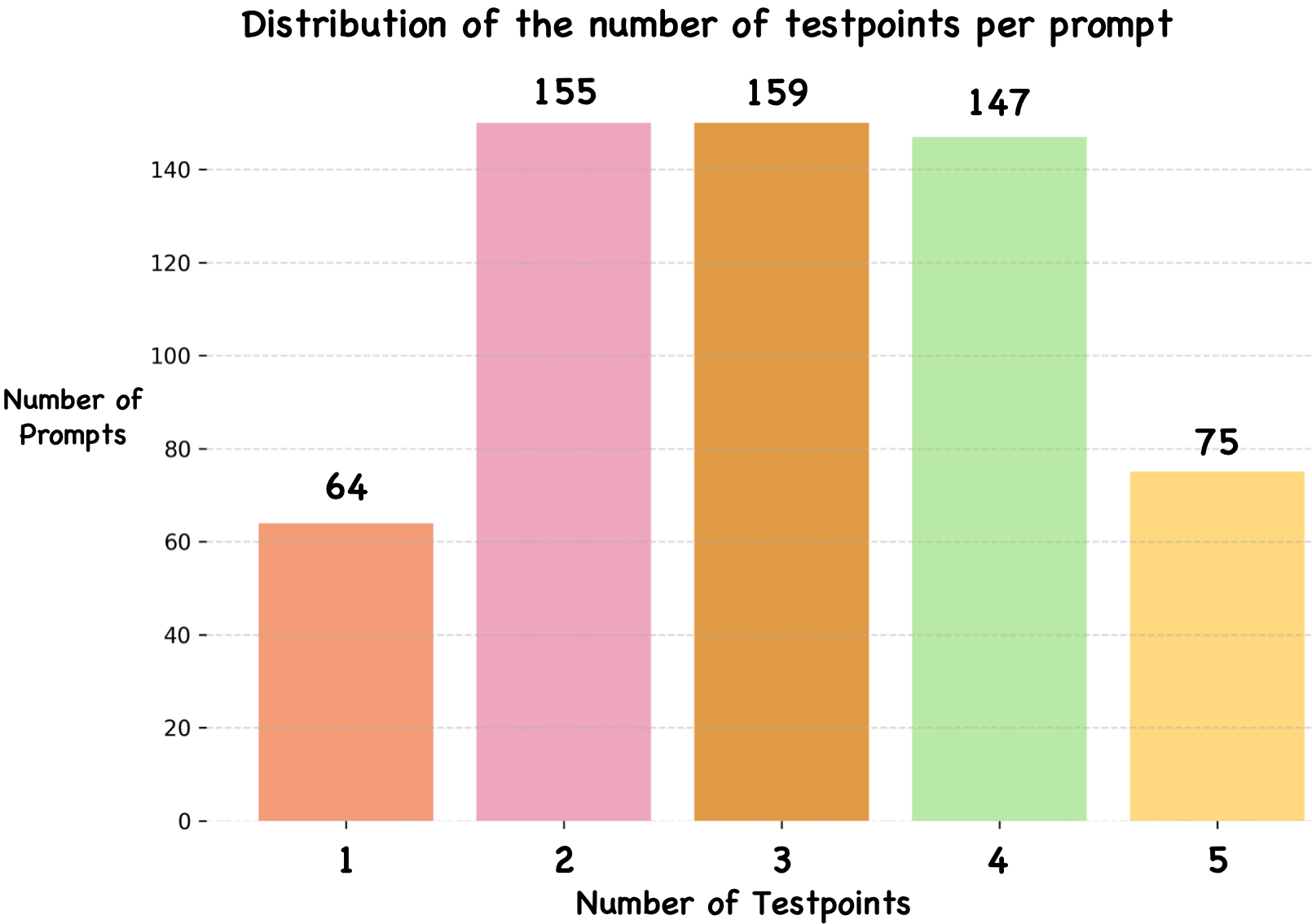
Recent advancements underscore the significant role of GRPO-based reinforcement learning methods and comprehensive benchmarking in enhancing and evaluating text-to-image (T2I) generation. However, (1) current methods employ pointwise reward models (RM) to score a group of generated images and compute their advantages through score normalization for policy optimization. Although effective, this reward score-maximization paradigm is susceptible to reward hacking, where scores increase but image quality deteriorates. This work reveals that the underlying cause is illusory advantage, induced by minimal reward score differences between generated images. After group normalization, these small differences are disproportionately amplified, driving the model to over-optimize for trivial gains and ultimately destabilizing the generation process. To this end, this paper proposes Pref-GRPO, the first pairwise preference reward-based GRPO method for T2I generation, which shifts the optimization objective from traditional reward score maximization to pairwise preference fitting, establishing a more stable training paradigm. Specifically, in each step, the images within a generated group are pairwise compared using preference RM, and their win rate is calculated as the reward signal for policy optimization. Extensive experiments show that Pref-GRPO effectively differentiates subtle image quality differences, offering more stable advantages than pointwise scoring, thus mitigating the reward hacking problem. (2) Additionally, existing T2I benchmarks are limited to coarse evaluation criteria, covering only a narrow range of sub-dimensions and lacking fine-grained evaluation at the individual sub-dimension level, thereby hindering comprehensive assessment of T2I models. Therefore, this paper proposes UniGenBench, a unified T2I generation benchmark. Specifically, our benchmark comprises 600 prompts spanning 5 main prompt themes and 20 subthemes, designed to evaluate T2I models’ semantic consistency across 10 primary and 27 sub evaluation criteria, with each prompt assessing multiple testpoints. Using the general world knowledge and fine-grained image understanding capabilities of Multi-modal Large Language Model (MLLM), we propose an effective pipeline for benchmark construction and evaluation. Through meticulous benchmarking of both open and closed-source T2I models, we uncover their strengths and weaknesses across various fine-grained aspects, and also demonstrate the effectiveness of our proposed Pref-GRPO.


@article{Pref-GRPO&UniGenBench,
title={Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning},
author={Wang, Yibin and Li, Zhimin and Zang, Yuhang and Zhou, Yujie and Bu, Jiazi and Wang, Chunyu and Lu, Qinglin and Jin, Cheng and Wang, Jiaqi},
journal={arXiv preprint arXiv:2508.20751},
year={2025}
}