Current human image customization methods leverage Stable Diffusion (SD) for its rich semantic prior. However, since SD is not specifically designed for human-oriented generation, these methods often require extensive fine-tuning on large-scale datasets, which renders them susceptible to overfitting and hinders their ability to personalize individuals with previously unseen styles. Moreover, these methods extensively focus on single-concept human image synthesis and lack the flexibility to customize individuals using multiple given concepts, thereby impeding their broader practical application. This paper proposes MagicFace, a novel training-free method for multi-concept universal-style human image personalized synthesis. Our core idea is to simulate how humans create images given specific concepts, i.e., first establish a semantic layout considering factors such as concepts' shape and posture, then optimize details by comparing with concepts at the pixel level. To implement this process, we introduce a coarse-to-fine generation pipeline, involving two sequential stages: semantic layout construction and concept feature injection. This is achieved by our Reference-aware Self-Attention (RSA) and Region-grouped Blend Attention (RBA) mechanisms. In the first stage, RSA enables the latent image to query features from all reference concepts simultaneously, extracting the overall semantic understanding to facilitate the initial semantic layout establishment. In the second stage, we employ an attention-based semantic segmentation method to pinpoint the latent generated regions of all concepts at each step. Following this, RBA divides the pixels of the latent image into semantic groups, with each group querying fine-grained features from the corresponding reference concept. Notably, our method empowers users to freely control the influence of each concept on customization through a weighted mask strategy. Extensive experiments demonstrate the superiority of MagicFace in both single- and multi-concept human image customization.
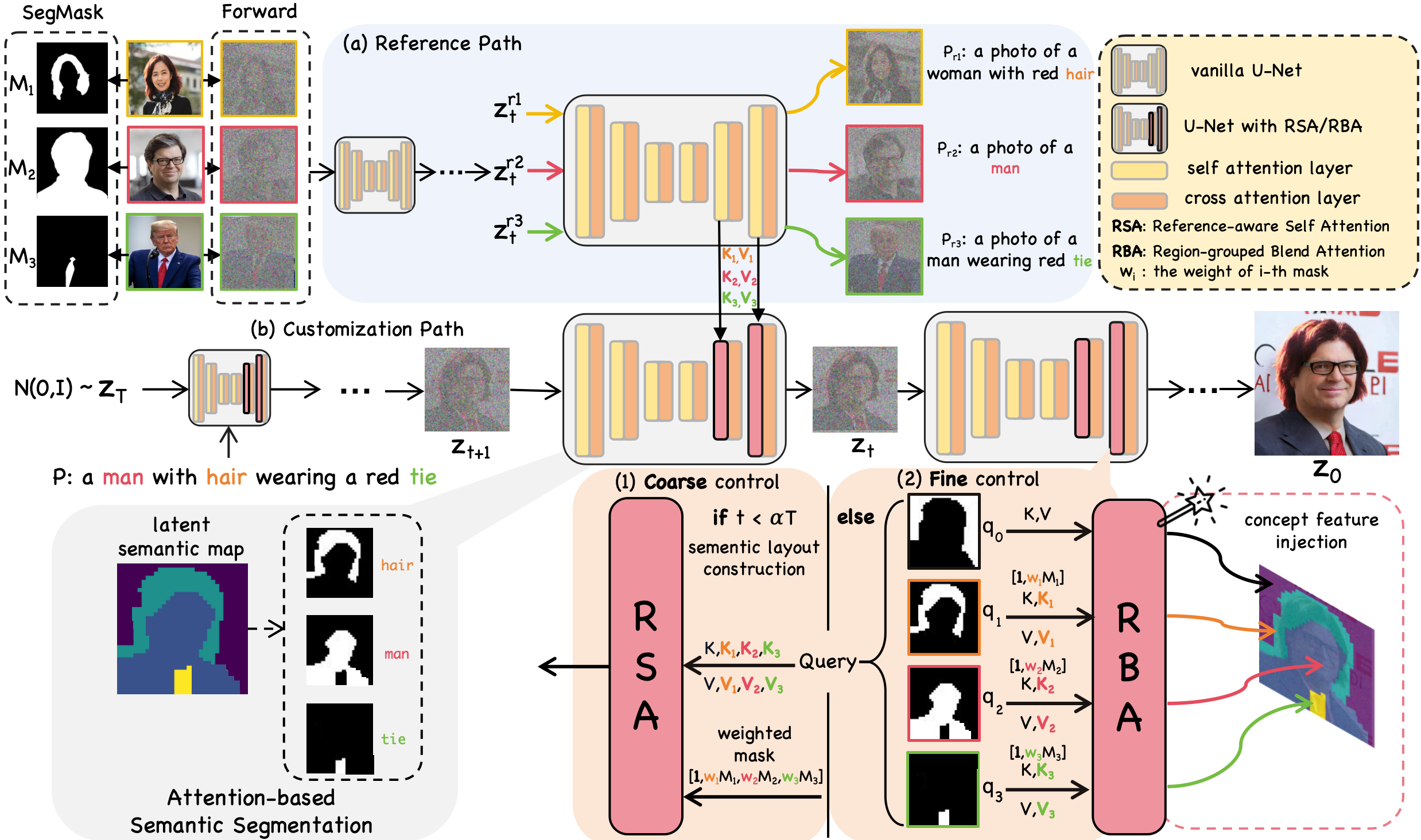
Given reference images, their segmentation masks, and text prompts, we generate personalized image z0 aligned to the target prompt $P$. The sampling pipeline consists of two paths: (a) the reference path and (b) the customization path. In (a), we first employ a diffusion forward process on the reference images. Then, the noised reference latents are input into vanilla U-Net. In (b), we first sample a Gaussian noise zT and introduce a coarse-to-fine generation process involving two stages: semantic layout construction and concept feature injection. At each step t, we pass latent zt to our modified U-Net: (1) in the first stage, we employ RSA to integrate the features from the reference path to facilitate the initial semantic scene construction; (2) in the second stage, we first obtain the latent semantic map of zt via attention-based segmentation method. Based on this, RBA divides the latent image and ensures fine-grained feature injection for each generated concept. A weighted mask strategy is adopted to ensure the model focuses more on given concepts.

Comparisons of human-centric subject-to-image generation.

Comparisons of multi-concept human customization.

Human customization in photorealism style.
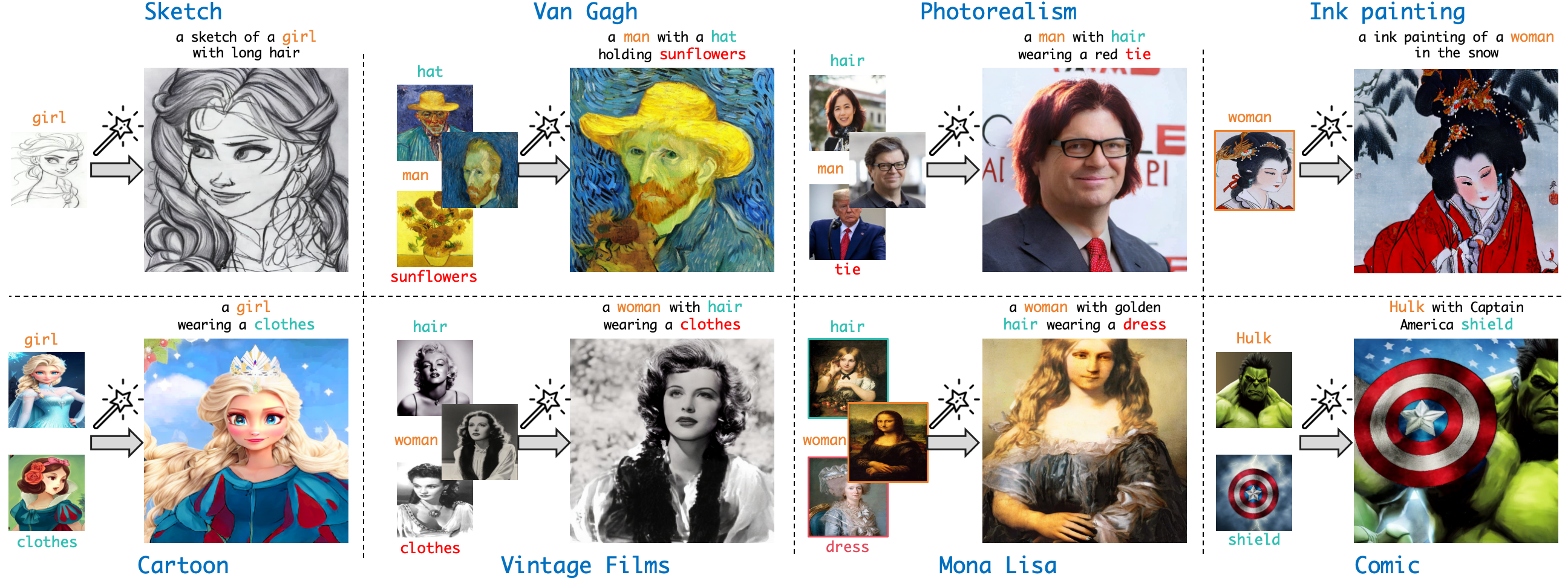
Human customization in diverse styles.
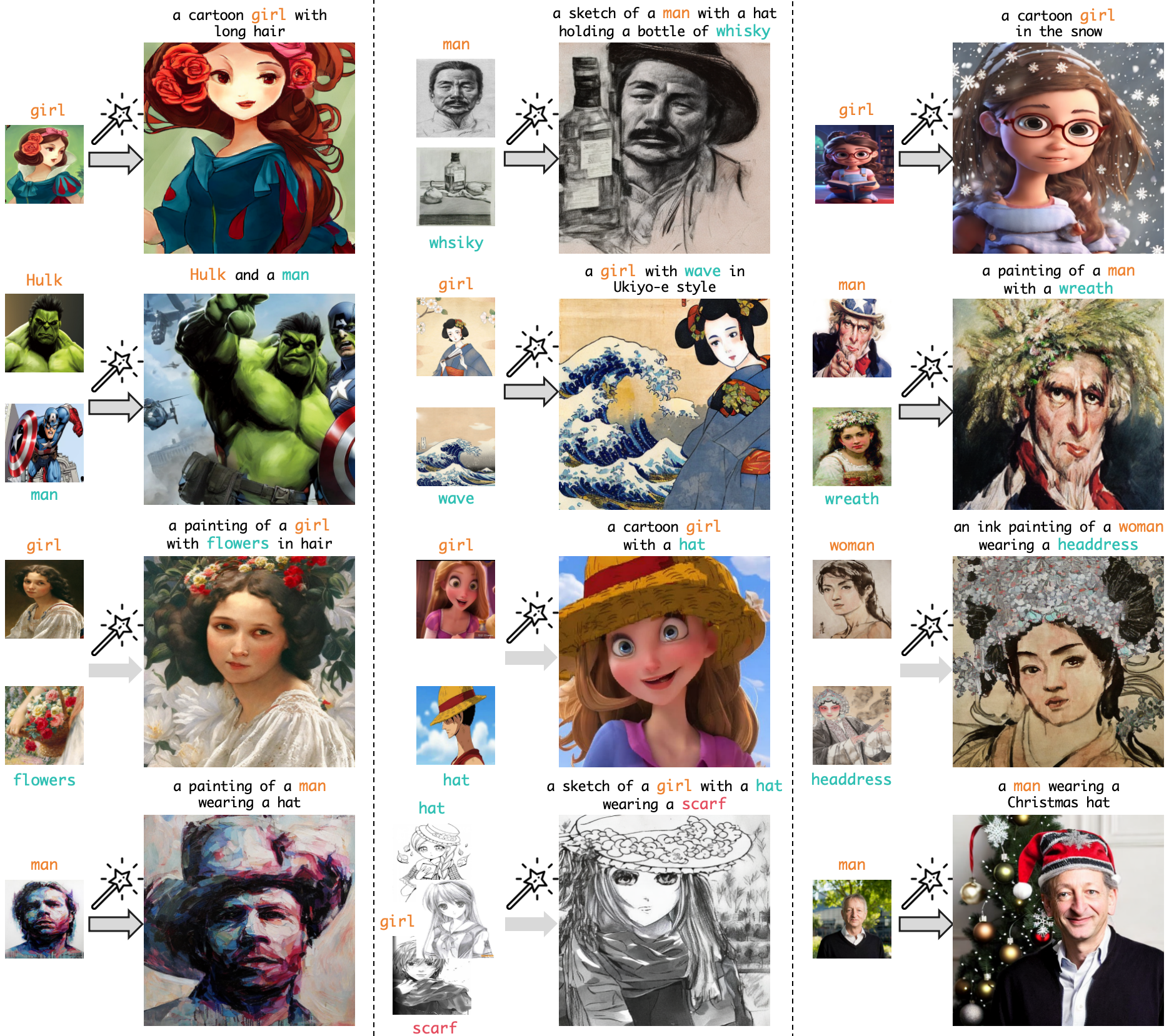
MagicFace is also highly effective for texture transfer. By precisely injecting features from input images, our method seamlessly integrates these appearances into generated objects, showcasing its versatility and effectiveness in diverse applications.
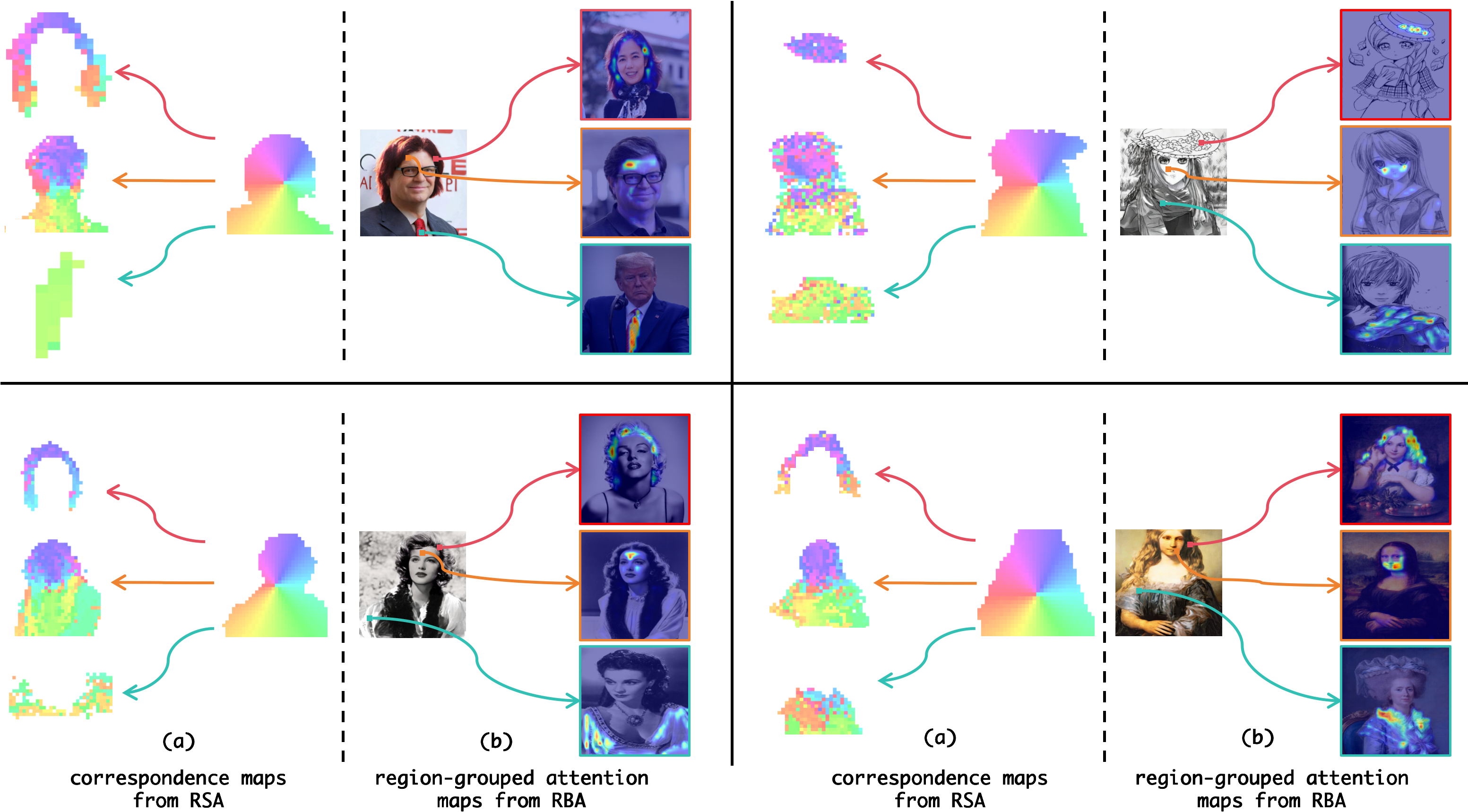
Correspondence maps and region-grouped attention maps visualization.
In (a), features with the highest similarity between the generated subject and the reference concepts are marked with the same color. (b) the results of features in colored boxes querying their reference concept keys.
@article{MagicFace,
title={MagicFace: Training-free Universal-Style Human Image Customized Synthesis},
author={Yibin Wang and Weizhong Zhang and Cheng Jin},
journal={arXiv preprint arXiv:2408.07433},
year={2024}
}